Nginx+Nacos2.2.0搭建集群遇坑指南
Nginx+Nacos2.2.0搭建集群遇坑指南
这几天刚刚开始学习Nacos,恰好重磅升级的Nacos2.2.0正式版刚刚发布不久,我直接忽略了老师讲解使用的1.1.4版本和SpringCloudAlibaba2.2.9版本推荐的2.1.0,直接选择了2.2.0,后者选择2.1.0和2.2.0的关系倒不是很大,但是1.x和2.x有太多的不一样,导致我花了两整天的时间捣鼓遇到的一个又一个坑。
坑一:64位jdk8+
启动Nacos后通过start.out看到总是报错,错误信息是:
1 | org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'instanceOperatorClientImpl' |
我又安装了Nacos1.1.4尝试,结果成功启动。那这就很可能是环境问题,打开Nacos官网手册一看,首页就是:
然后我就查了我在linux上的环境,也没有什么错误啊,直到过了很久才发现我的jdk是x86即32位,换了x64之后成功启动。
坑2:Nacos2.x使用grpc通信
在Nacos集群,Nginx反向代理都完成后,我测试了Nacos作为配置中心的功能,结果很完美。就当我测试最后一步作为服务注册中心功能时,微服务又报错:
1 | com.alibaba.nacos.api.exception.NacosException: Client not connected, current status:STARTING |
nginx反向代理配置:
1 | upstream nacoscluster{ |
微服务配置:
1 | spring: |
配置看起来和老师一模一样,那就还是版本新特性问题,其实Nacos2.x服务端是支持http2和grpc两种通信方式的,但是我们Maven中导入的客户端版本是2.1.0,client客户端在2.x版本中使用 grpc 调用,那显然我们使用nginx进行http代理是不靠谱的。

解决方法一,使用http通信:
那第一种解决方法就是直接把客户端版本降低,替换成1.x版本,问题成功解决:
1 | <dependency> |
但是,既然选择了Nacos2.x服务端,那最好还是用对应的2.x客户端,毕竟据官方宣传Nacos2.0的性能相较于1.x提升近10倍,2.x默认使用grpc调用通信原因就是grpc的低延迟和高吞吐量特性。
解决方法二,Nginx使用TCP代理:
官网有这样一句话使用VIP/nginx请求时,需要配置成TCP转发,不能配置http2转发,否则连接会被nginx断开。Nginx如何实现TCP转发有很多博文,这里就不写了,主要是需要添加一个插件–with-stream。
nginx添加配置(http的不用动,浏览器访问依旧需要):
1 | stream{ |
注意这个stream是和上面的http平级的。至于端口为什么比http里面的多1000,是因为我们上面提到的Nacos2.x客户端和服务端使用grpc调用,这里的端口是grpc端口,GRPC port = 主端口 + grpc端口偏移量,Nacos源码中设置偏移量默认1000。
微服务注册配置是不需要修改的,因为微服务注册配置的是主端口,所以还是1111。
1 | spring: |
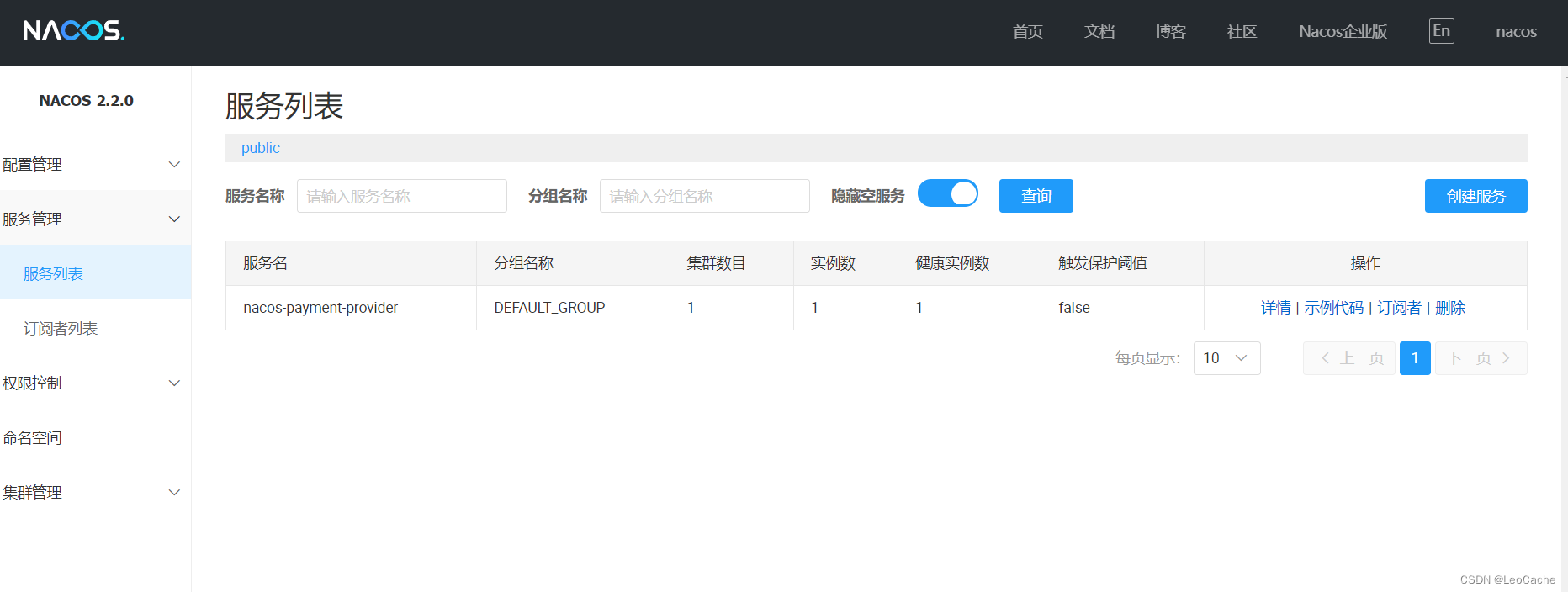
最后,终于完成了Nacos2.2.0+Nginx实现Nacos集群的配置,成功将微服务注册:
新版本选用问题
我在使用东西的时候总爱去使用一些较为新的版本,与老师使用的不同,很可能就会导致很多兼容问题。但是我感觉遇到这种问题通过自己一步步的解决可能比使用与老师一样的版本按部就班的要更有意义。因为在微服务时代,性能的优化是非常重要的,新版本肯定在性能上比旧版本有不小提升,就比如Nacos2.x比Nacos1.x有近10倍性能提升,但是新版本也不是随便使用的,你不能使用一个SpringCloudAlibaba低版本与最新的Nacos或者其他组件去搭建,那问题肯定会更多,还是要遵循官方的版本关系建议。


























